


Probabilistic scores
Quantile loss
The quantile score is a linear expression of the prediction error :
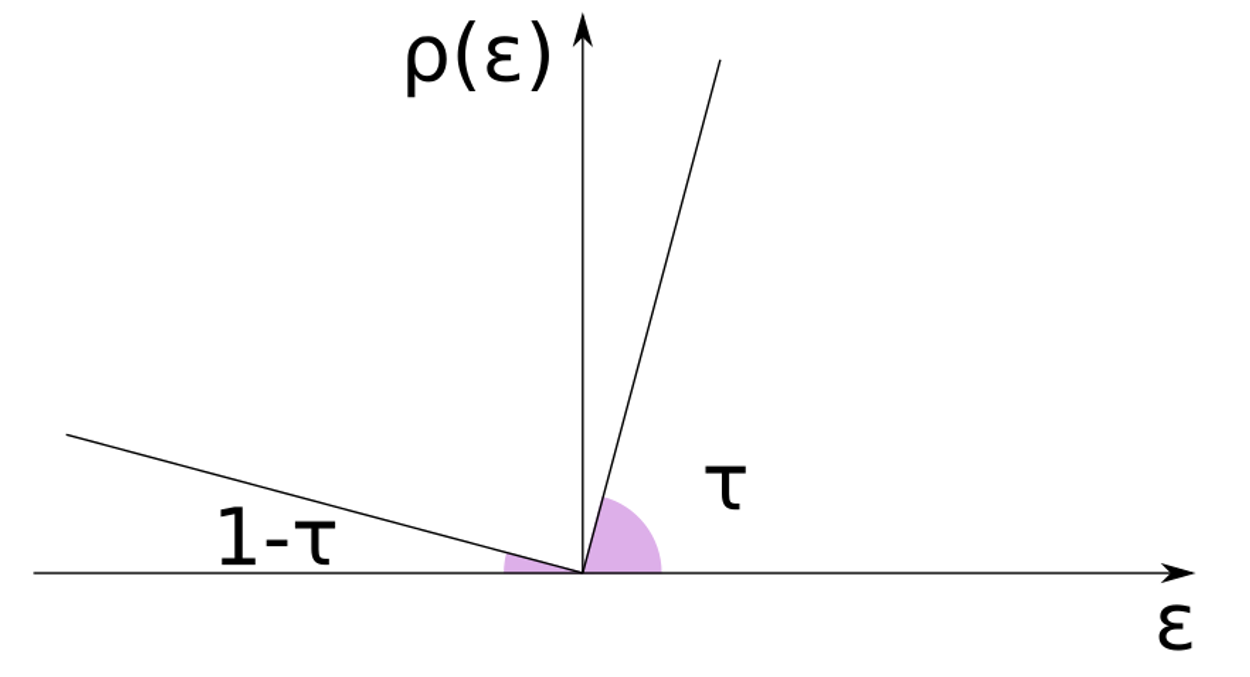
that, when minimized, is guaranteed to fit the -level quantile, regardless of the underlying distribution. We can see this minimizing the expected value of the quantile loss over the data distribution
We can split the expectation integral in two parts, under and above the predicted quantile:
and find the optimal value by deriving the expression by and setting it to 0:
The first integral is the definition of the CDF , while the second is :
CRPS
The continuous rank probability score is defined as the quadratic distance between the forecasted CDF and the empirical one. That is, CRPS computes how close the predicted quantiles are w.r.t. the data distribution:
Definition
The CRPS is a proper scoring rule. Hence its minimum is obtained when and the data distribution are equal
The first expression states that the CRPS can be computed by Montecarlo sampling from
The second expression states that CRPS can be computed as the mean value of the quantile score over equispaced predicted quantiles
Since CRSP depends on the scale of the signal, in order to compare it across different time series, it must be normalized with a benchmark forecaster:
Reliability
A complementary measure of goodness of fit for a probabilistic prediction is reliability:
That is, reliability computes the average number of times the observations fall below a given quantile.
CRPS and reliability can be easily computed. Here is a vector of observed data and is a matrix whose rows contain the predicted tau-quantile:
Python
Copy
def quantile_score(q, y, q_vect=np.arange(10)/10):
qs = {}
for tau, q_i in zip(q_vect, q):
err_tau = q_i - y
I = (err_tau > 0).astype(int)
qs[alpha] = np.mean((I - tau) * err_tau)
Python
Copy
def reliability(q, y, q_vect=np.arange(10)/10):
res = {}
for alpha, q_i in zip(q_vect, q):
res[alpha] = np.mean(y < q_i)
The CRPS is then the mean value of qs
 Which is better
Which is better
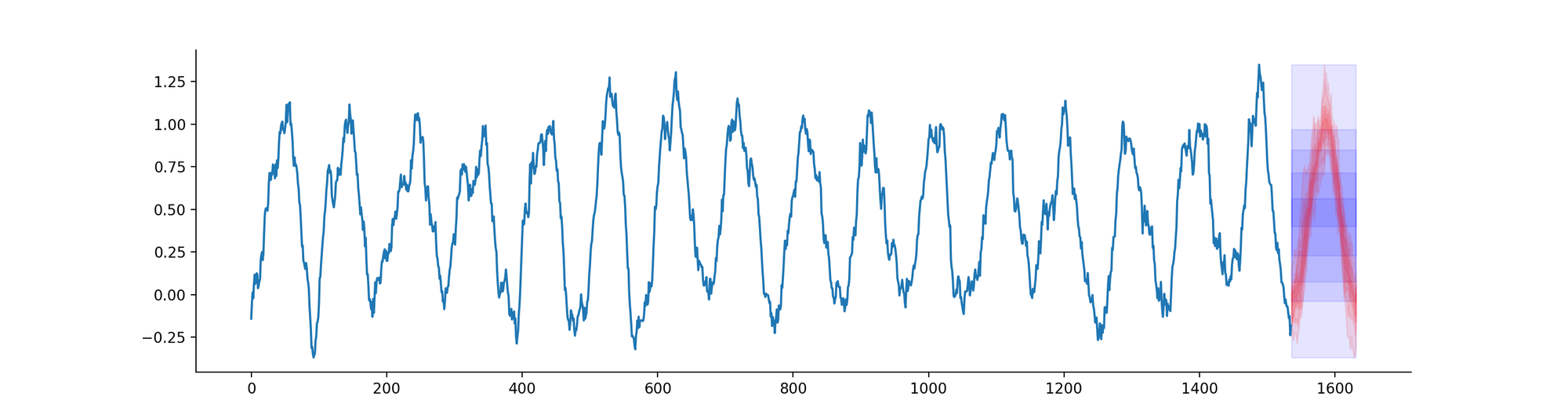
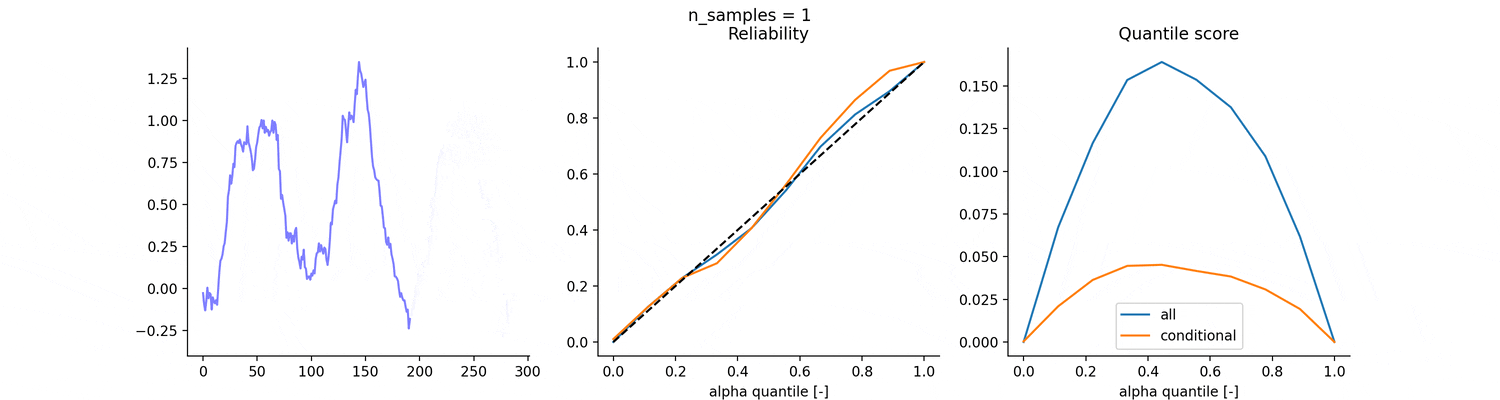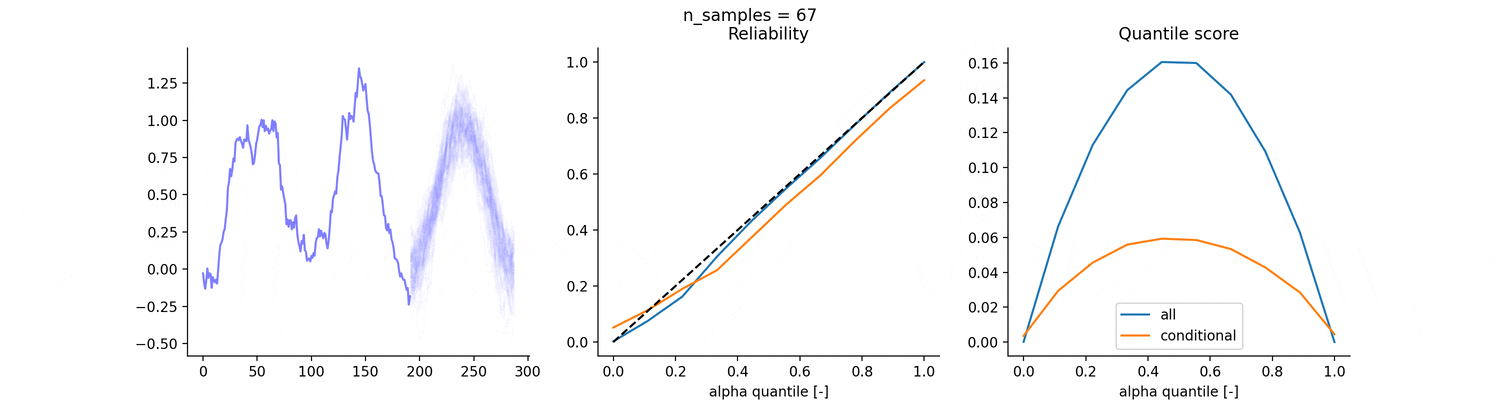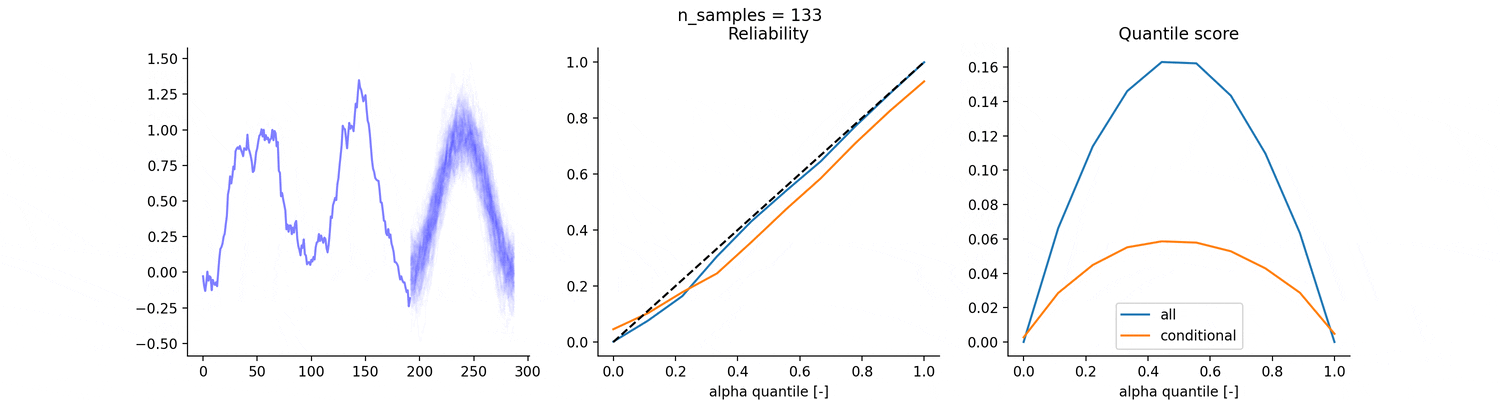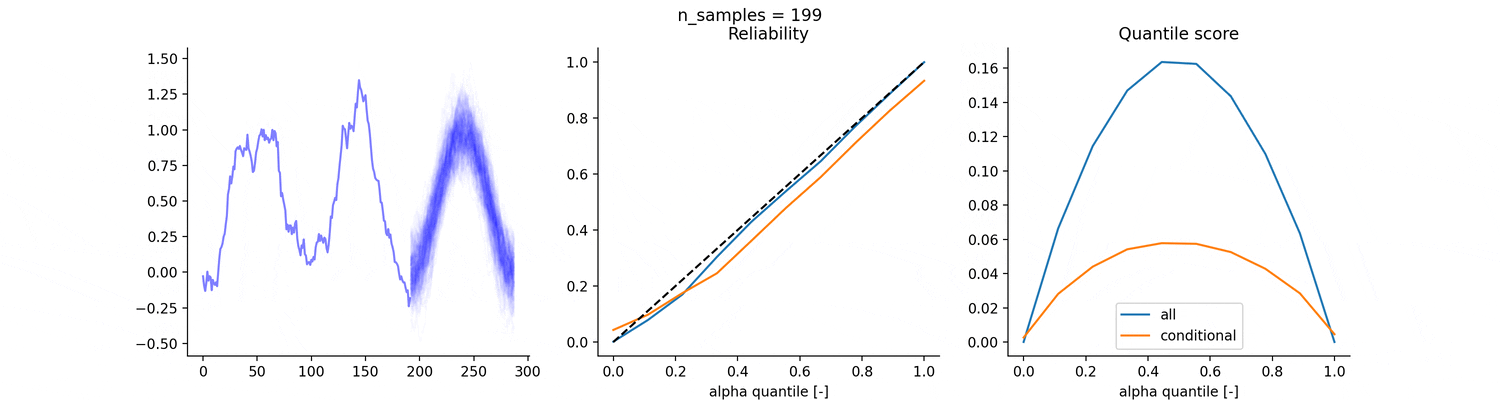
Consider the following 16 days dataset, for which we know the data generation process. We consider the following two predictions for the quantiles:
the empirical quantiles over the entire dataset (blue)
the empirical quantiles, conditional to each hour of the day (red)
If we generate the dataset again S times and evaluate the two strategies on the 17th day, which strategy will perform better in term of reliability and quantile scores?
Distribution-agnostic probabilistic prediction methods
Naive bootstrap method
This method consists of:
train a model on
retrieve the error on the training set
superimpose quantiles of to the predictions, so that the final confidence interval is
fast, distribution and model agnostic
Using the training set for retrieving the empirical distribution makes the prediction intervals over-confident
Quantile regression
We have seen that the minimizer of the quantile loss is the empirical tau-quantile, regardless of the underlying distribution → quantile regression consists of training a regressor to directly minimize the quantile loss .
agnostic to the data distribution
can be directly minimized by generic regressors (LightGBM, kNN, NNs)
independent models for different steps ahead
We need to train separate models for separate steps-ahead AND quantile levels
Since quantiles are independently trained, we can experience quantile crossing
The M5 competition winner for the probabilistic track used a set of LightGBM, minimizing the quantile loss.
Conformal predictions
Conformal prediction is based on the idea of constructing a set of hypothesis tests to determine whether a new observation is consistent with the previously observed data. The test results are then used to construct a prediction interval, which is guaranteed to contain the true value with a certain probability.
Conformal prediction doesn’t require IID assumption but requires exchangeability: any permutation of the dataset observations is equiprobable. However, the time steps within a time-series are inherently non-exchangeable due to temporal dependencies.
Given a dataset , CP generates prediction intervals such that:
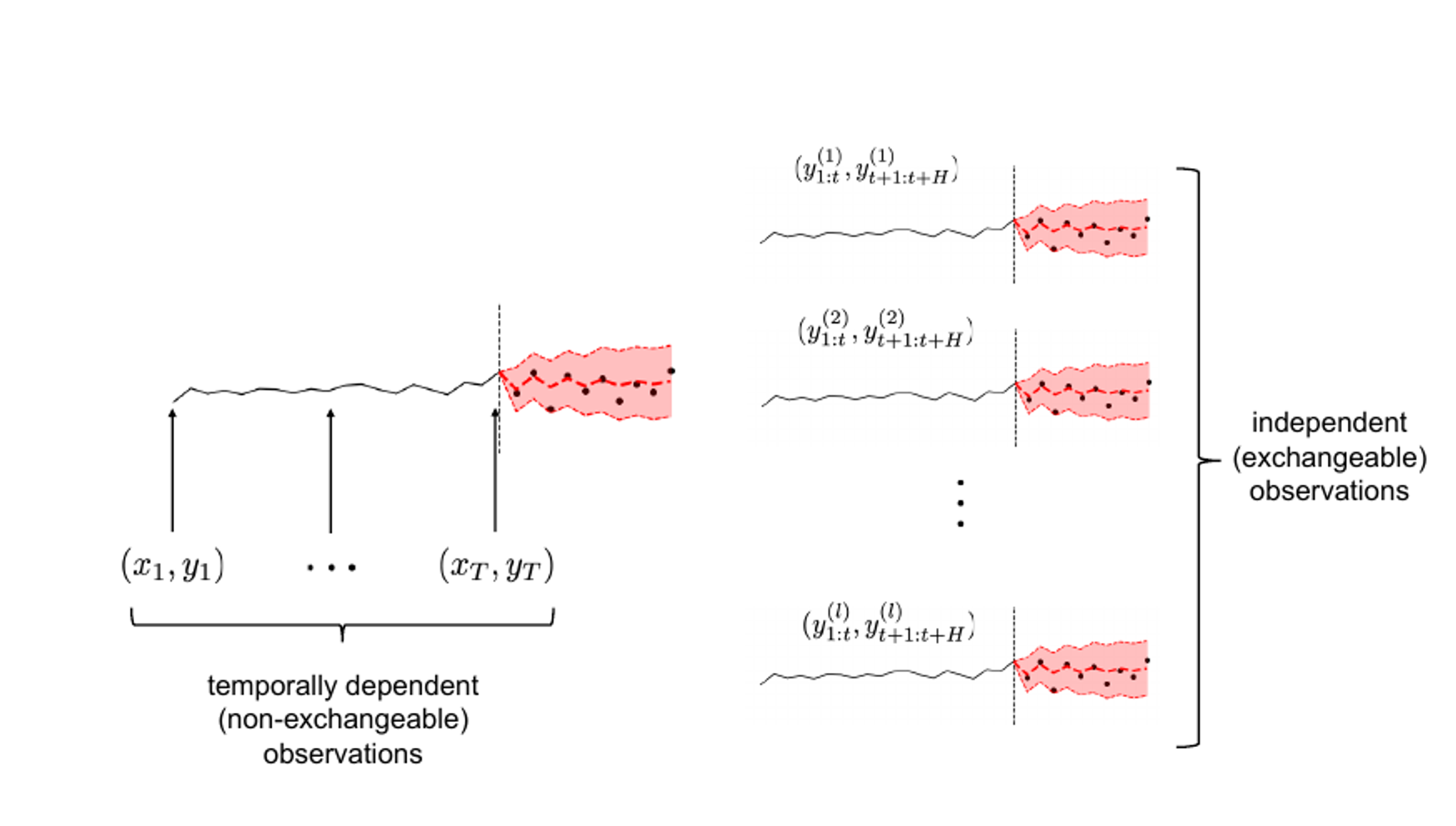
Left: time series can’t be considered exchangeable. Right: exchangeability can be obtained considering several instances of multiple step-ahead forecasting (=embeddings).
CP theory is pretty involved, but the steps of the basic method can be summarized as:
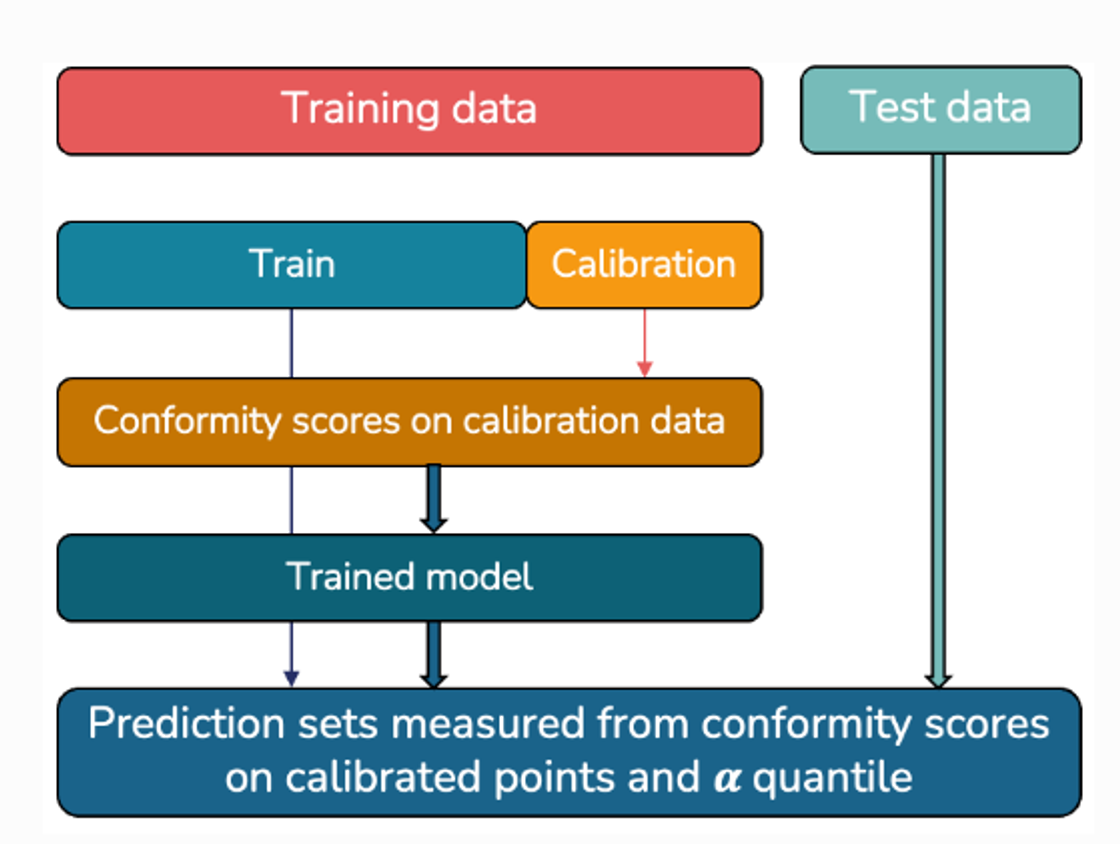
Split the dataset in training and calibration
Train a forecasting model on
Use the calibration set to obtain a non-conformity score: a measure of how much new predictions differ from observed ones. Usually the non-conformity score is the absolute value of the prediction error.
Compute prediction intervals as where and is the quantile of the prediction error on , ordered with the conformity score.
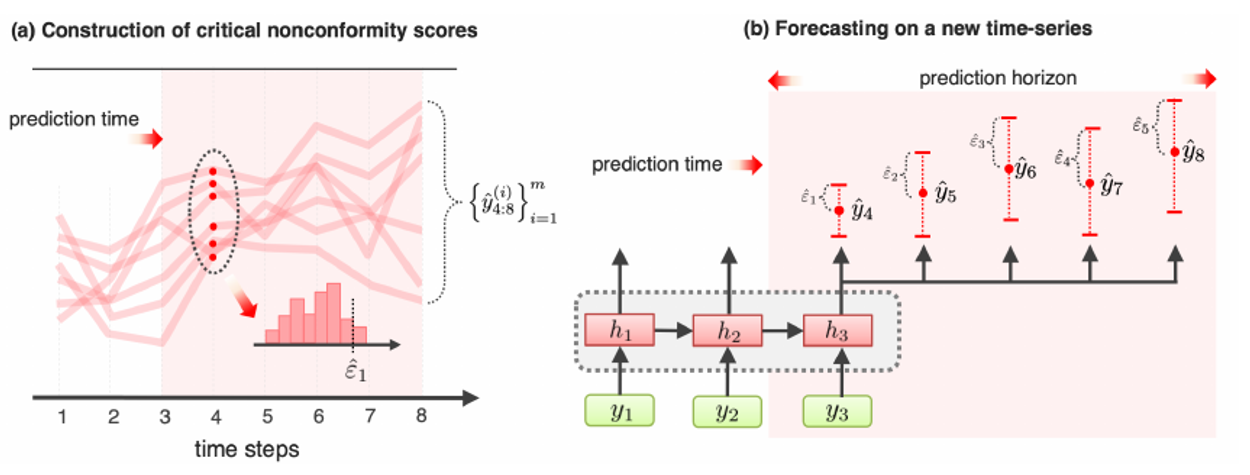
CP intervals for multi step-ahead predictions: each step ahead has its own error distribution
When the non-conformity score is the prediction error, this method corresponds to the naive bootstrap method.
The only difference is that for multi-step-ahead forecasts, CP applies a Bonferroni correction: instead of taking the quantile, we take the quantile, where the sign depends on whether we are computing a quantile lower (-) than 0.5 or higher (+).
In the base form, CP sacrifices part of the dataset for calibration. To increase data efficiency, CP can be combined with CV using the following scheme:
A CV scheme is applied:
For each split, confidence intervals are generated from perturbed models
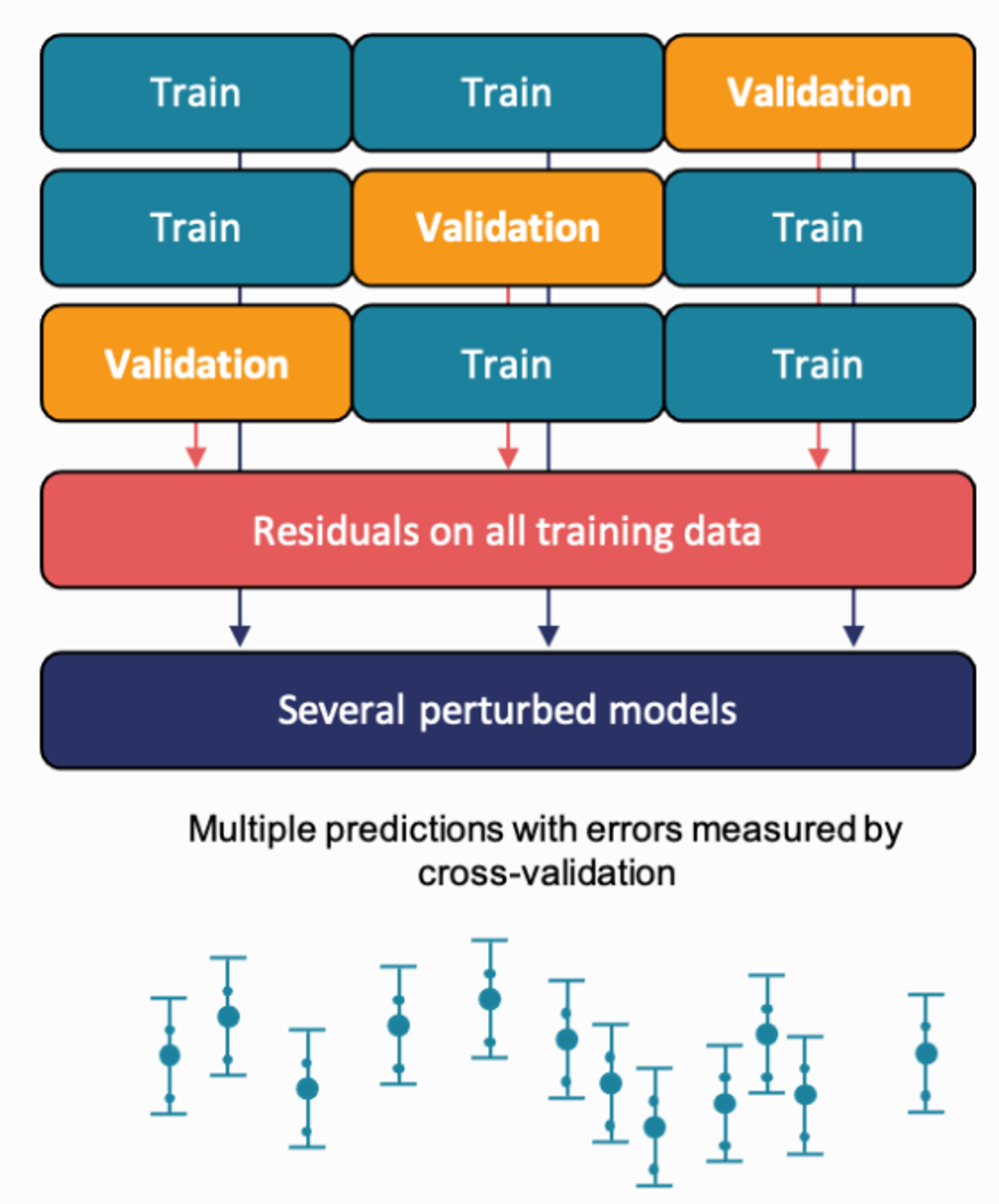
Each fold is composed of the following steps:
A model is trained on part of the training data
conformity scores are obtained on the rest of the training data
The test data
Variants of CP, as conformalized quantile regression (CQR), use the quantile loss to better calibrate the prediction intervals on heteroscedastic data.
non-parametric, distribution-agnostic
can produce consistent probabilistic distributions for multiple steps ahead
has been applied in a wide range of domains, including finance, medicine, and meteorology, among others.
different plug-and-play libraries, like MAPIE, provide CP intervals for scikit-learn compatible models
in the base form, it doesn’t produce conditional intervals
Advanced methods
Estimation of multivariate PDFs using copulas
Estimating time-varying and high-dimensional covariance matrices often limits existing methods to handling at most a few hundred dimensions or
requires making strong assumptions on the dependence between series
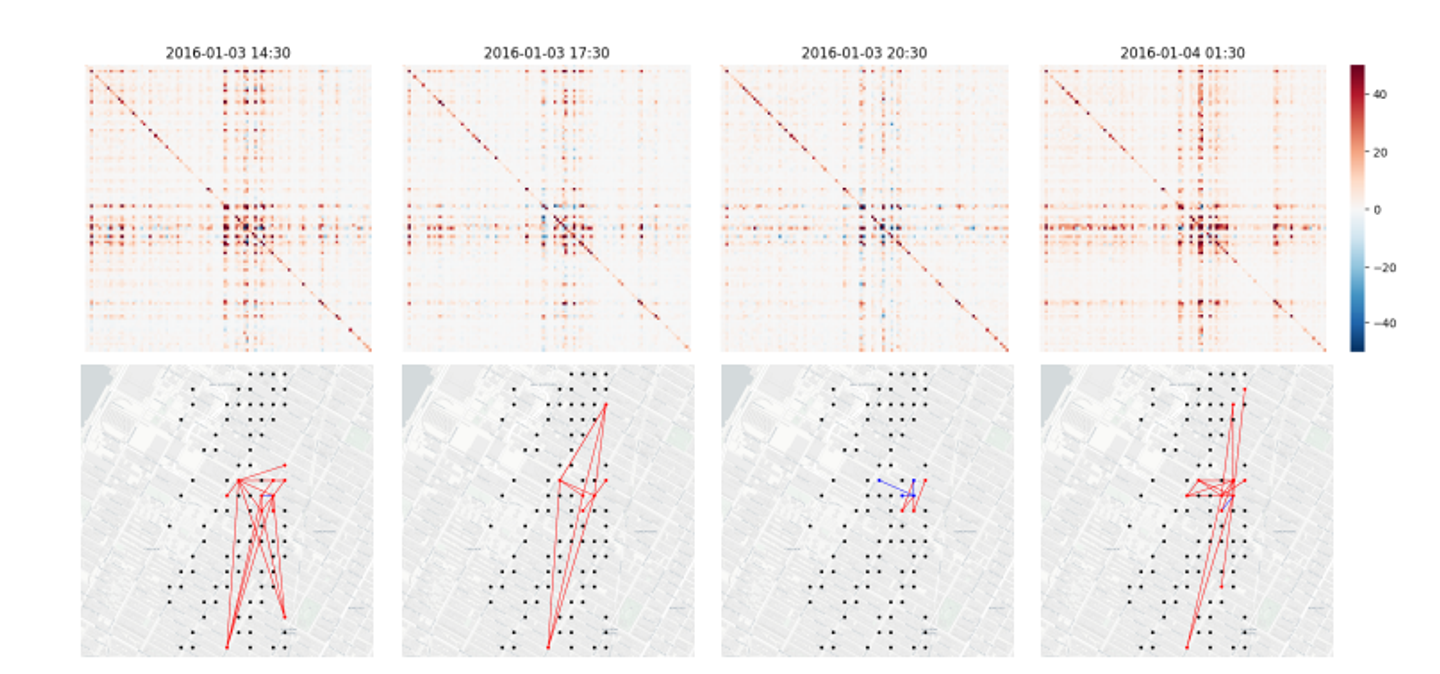
Time-varying covariance matrices for taxi traffic time series for 1214 locations in New-York at 4 different hours of a Sunday
Gaussian copula process output model to handle non-Gaussian marginal distributions
low-rank covariance structure to reduce the computational complexity
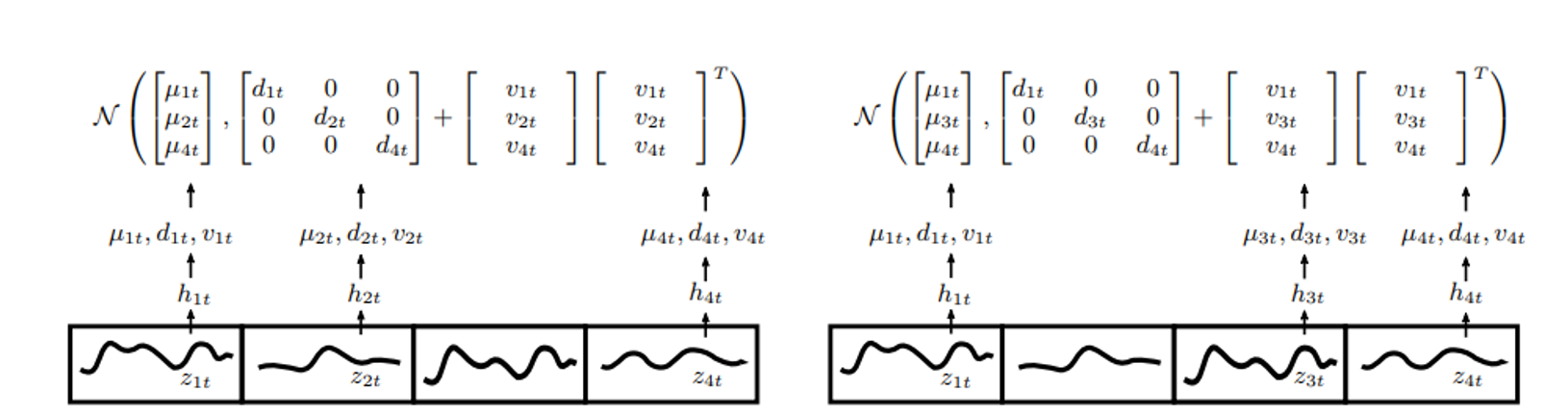
From “Salinas D. et al., High-Dimensional Multivariate Forecasting with Low-Rank Gaussian Copula Processes”, NeurIPS 2019
Scenario generation
Forecasting techniques usually generate different PDFs for different timesteps.
They do not directly output the whole joint distribution from which we could derive all the properties of the stochastic process.
As for the hierarchical reconciliation technique, usually, an ex-post method is used to produce scenarios.
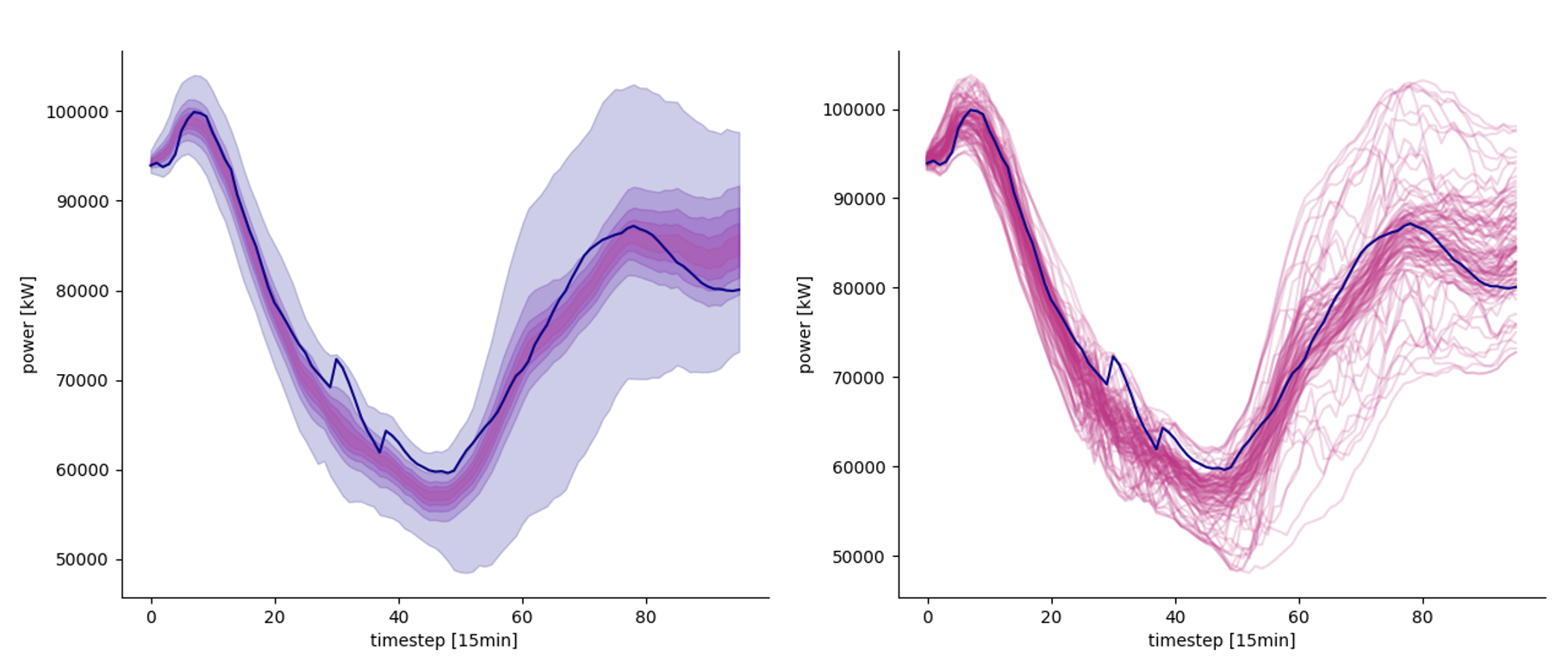
Left: predicted quantiles. Right: 100 different scenarios
Linking PDFs through correlation structure
Recall that we can generate new samples from a univariate distribution, known its analytical or empirical CDF , by means of the inverse probability transform:
…simply means that querying the CDF on the y axis will sample new observations whose density function is the original PDF
How can we sample from a multivariate distribution by independently query the marginals ?
if a method exists, it must produce consistent marginals → we can use multivariate uniform distribution with a dependence structure
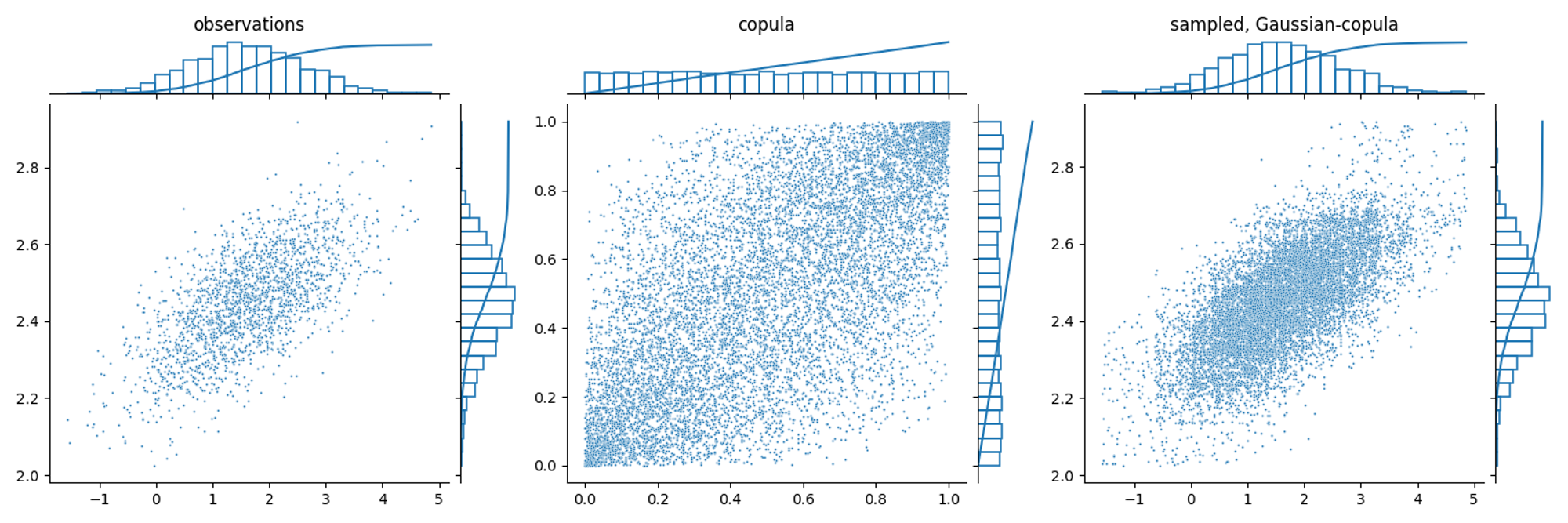
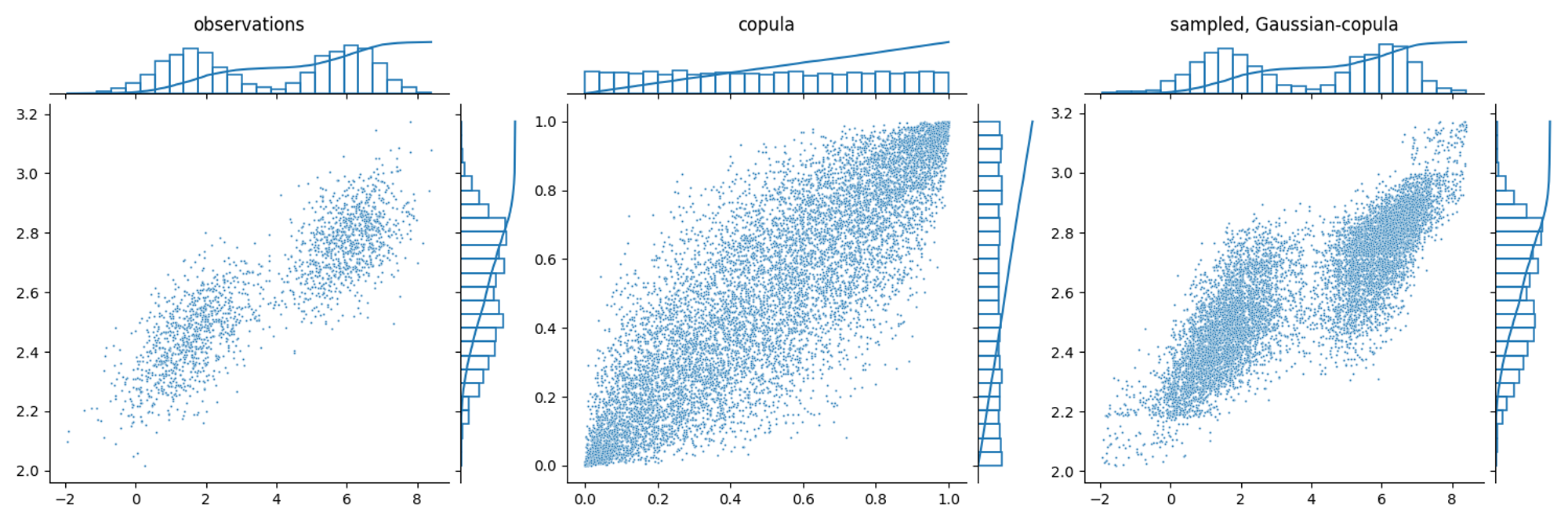
Copulas are multivariate CDFs with uniform marginals.
Sklar’s theorem states that any joint CDF can be expressed starting from its marginals, linked by a copula
For a lot of real multivariate processes, the covariance structure can be modeled using a multivariate Gaussian
estimate from the observed data
produce multivariate Gaussian samples, :
use the inverse probability transform to obtain uniform random variables in the [0, 1] range through the normal ECDF
query each marginal ECDF independently, but using the correlated uniform samples
Unimodal example
Imagine that we want to model the correlation between the first two steps ahead forecasts. We can use this method to create a generative model
1: Estimate from observation
2-3:
4:
Multimodal example
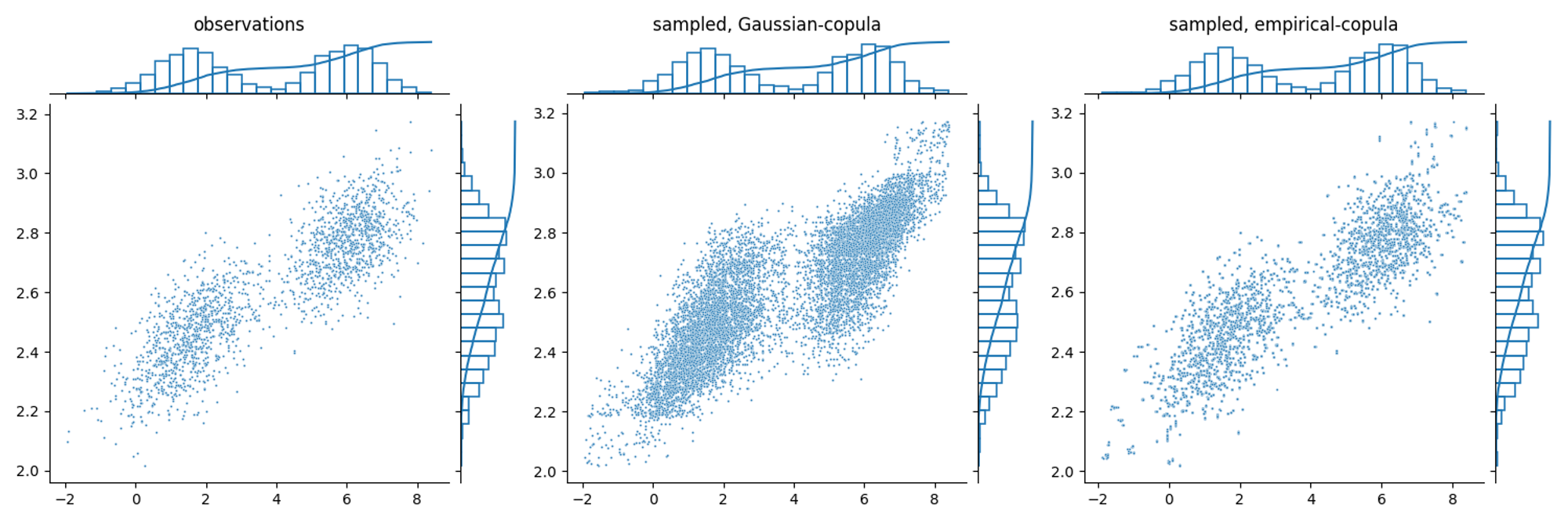
Gaussian correlation can also be applied to non-gaussian correlation structure or bimodal marginal distribution. However, in this case the generated samples won’t perfectly resemble the observed distributions.
Empirical copula coupling example
Another method is to directly use the observed copula structure to generate new samples.
Stochastic trees
Forecast scenarios can be used directly in robust optimization. Usually, when the dynamics of the decision process is important, scenarios are reduced into a stochastic tree representation of the uncertainty.
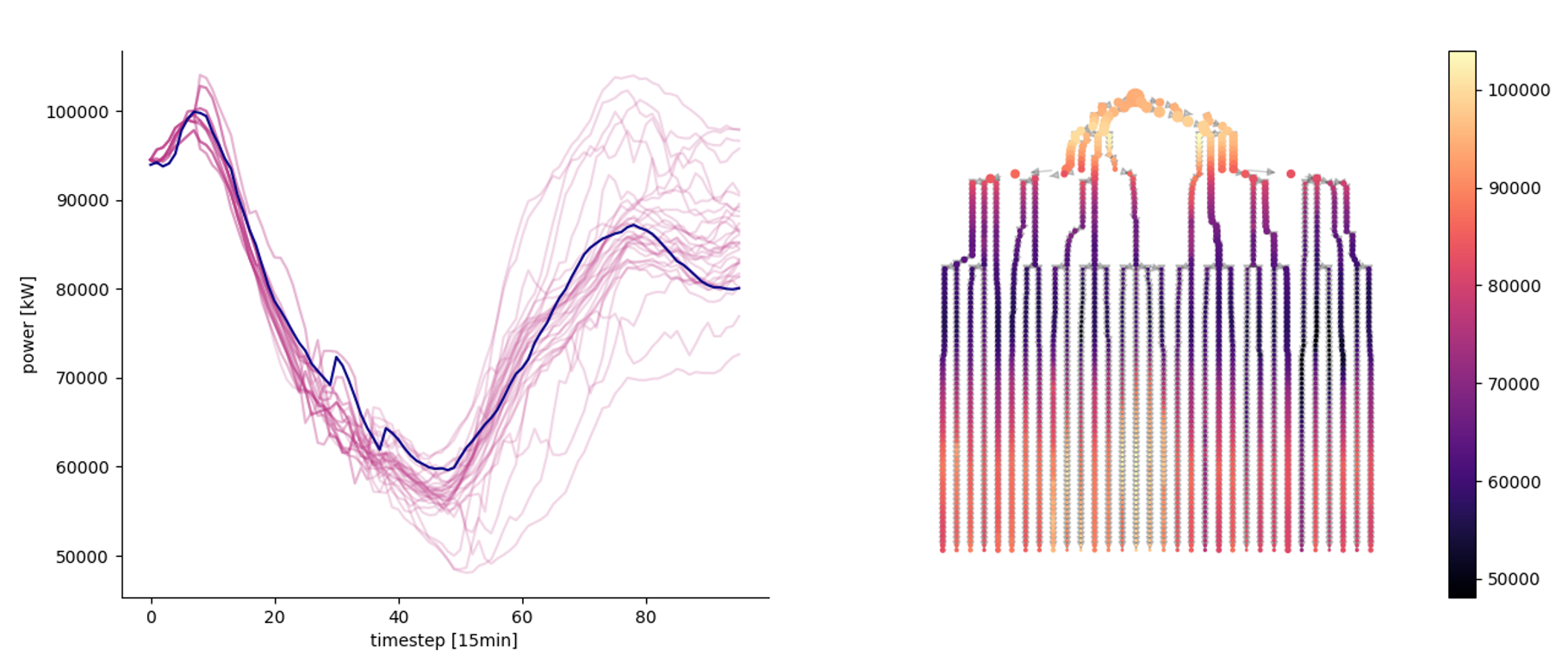
Left: a stochastic scenario tree obtained from the scenarios. Right: graph representation of the tree
Backward/Forward algorithm
The problem of reducing N scenarios to a tree is in general a hard problem. It is equivalent to an optimal transport problem, where we want minimize the distance of two multivariate distributions: the original one and the tree-encoded one.
Usually, some heuristics are applied.
The forward/backward methods consist of recursively pruning and merging scenarios based on their importance.
Backward method:
starting from T, aggregate closer scenarios based on a threshold distance
merged scenarios increase their weight = holding probability
the process is repeated back to t=0
Forward method
starting from t=0, aggregate closer scenarios based on a threshold distance
merged scenarios increase their weight = holding probability
the process is repeated back to t=T
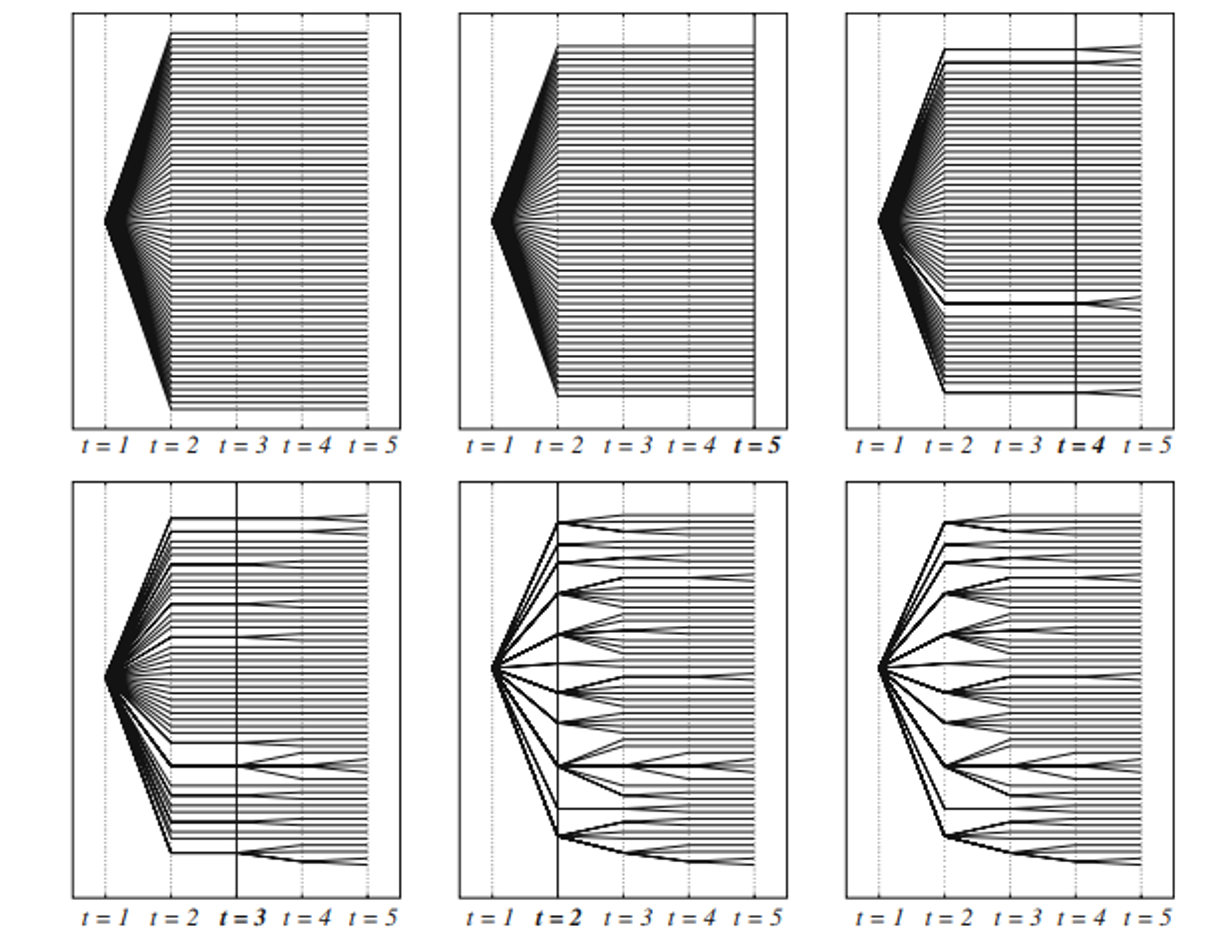
backward selection method
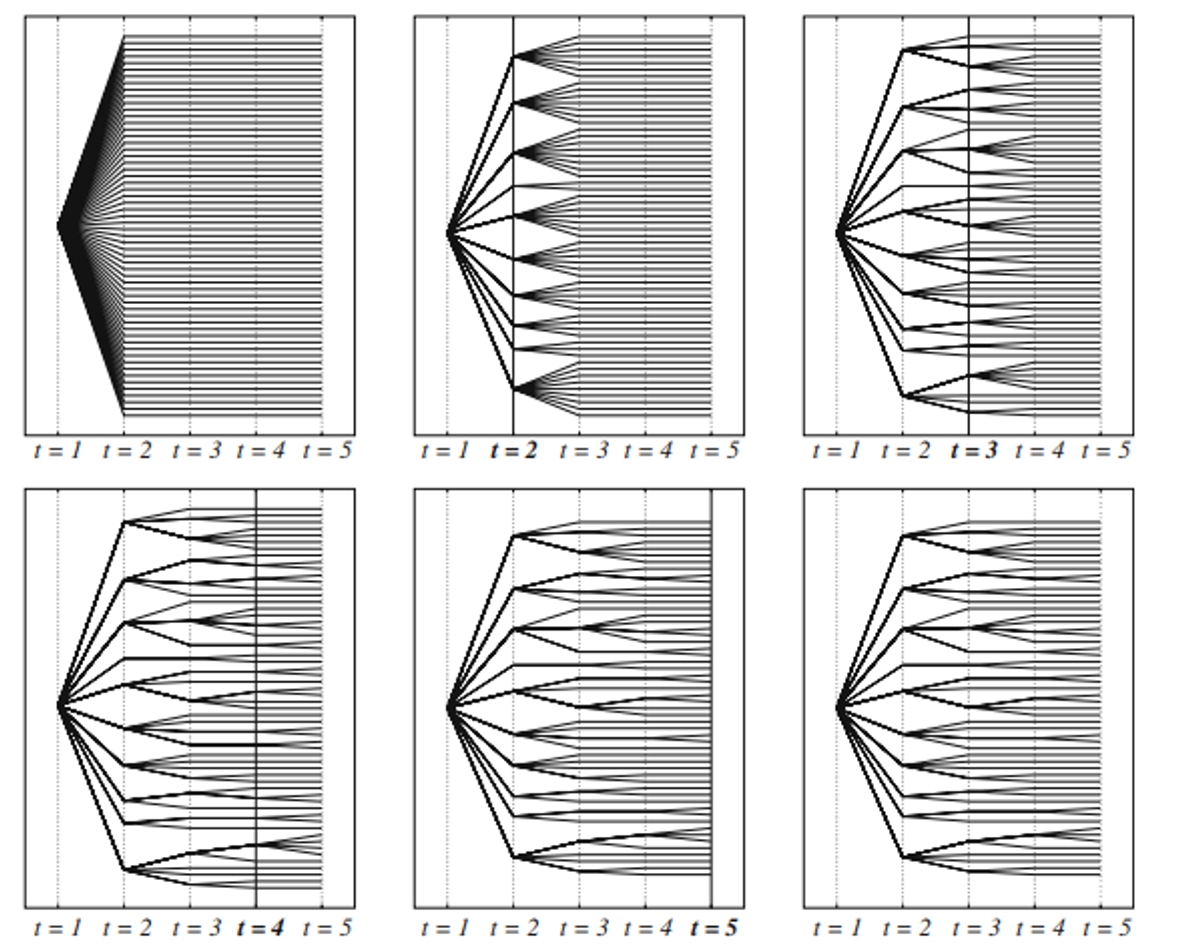
forward selection method
Neural gas & Direct loss minimization
The backward/forward heuristics do not allow for a fixed tree structure. Keeping a fixed tree structure is important if we want to pass it to a learning method, such as RL.
Two methods that keep a fixed structure are:
Neural Gas method: this is based on self-organizing maps. It’s an iterative method where “neurons” (nodes of the tree) are iteratively shifted based on their weighted distance from the data points. Convergence must be enforced by a shrinking learning rate.
Direct minimization of the original data distribution and the tree-encoded one. This can be achieved by gradient descent and auto-differentiation. Neither this method is guaranteed to converge to the global optimum, but it usually achieves good results.
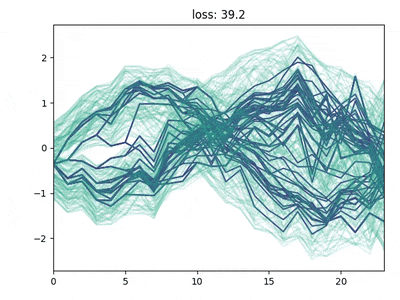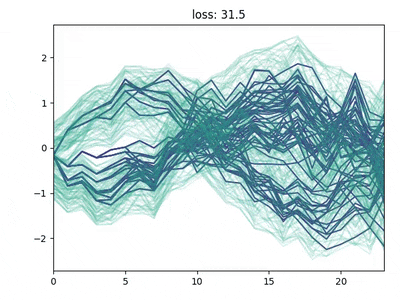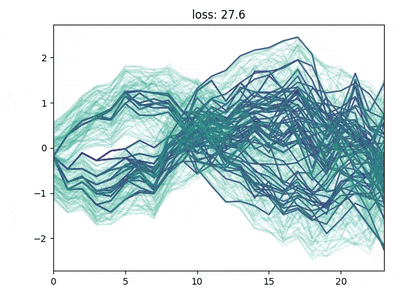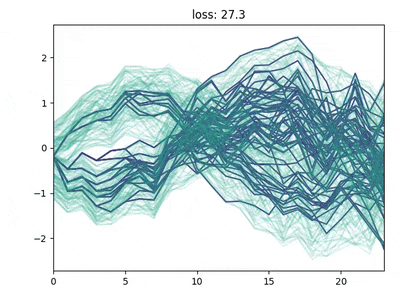
Neural gas for scenario tree reduction
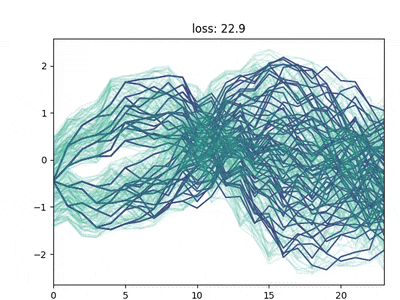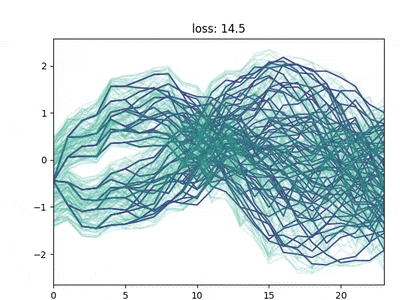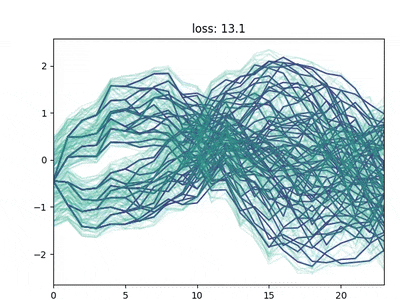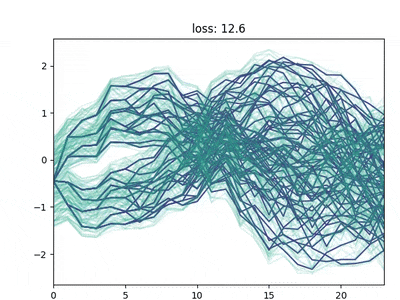
Direct differentiation of the reconstruction loss