



…there is a lot of potential in this particular area of forecasting and that developing new hierarchical forecasting methods, capable of reconciling forecasts so that the forecast error is minimized, not only on average but separately at each aggregation level, could provide substantial accuracy improvements.
Makridakis - “M5 accuracy competition: Results, findings, and conclusions”
2022, International Journal of Forecasting
Why consistent forecasts? Some examples
In many occasions, more than one signal must be forecasted. If we know that the signals are subject to an algebraic relation, we would like their forecast to respect it as well. Why?
Sales at different aggregation levels
Using consistent forecasts for sales at different aggregation levels is important in logistic planning. Inconsistent forecasts leads to unnecessary stock accumulations or lack of availability.
Water distribution network
Valves and pumps must be jointly controlled to keep water pressure within the network, as a function of the predicted demand. If the forecasted demand of the pipes drawing from the same vassel doesn’t sum up, our control actions will lead to a pressure change.
Distributed demand side management
Consider a district with a residential battery trying to perform peak shaving, and residential batteries trying to maximize self consumption. If forecasts are not consistent, the battery at the feeder will try to compensate actions of the privately-owned batteries, leading to an economic loss.
PV power production
Consider a region with a high penetration of PV power plants. Considering independent CDFs for the power produced by the PV power plants will result in an overall narrow CDF, since errors will tend to compensate for each other. In practice, the predictions of PV power plants of the same region have highly correlated errors, since all heavily depend on the same irradiance and temperature forecasts. Probabilistic reconciliation can produce more accurate CDF of the total produced power.
Another reason to work on reconciliation techniques is that, if the number of TS to forecast is high, it is hard to directly produce a set of consistent by design forecasts. It’s a good idea to use well-known techniques and use a post-processing step to reconcile the forecasts.
Background
Given a set of signals ,
Forecast reconciliation refers to the following two-steps procedure:
produce the base forecasts
produce a set of reconciled forecasts which respect some linear relation:
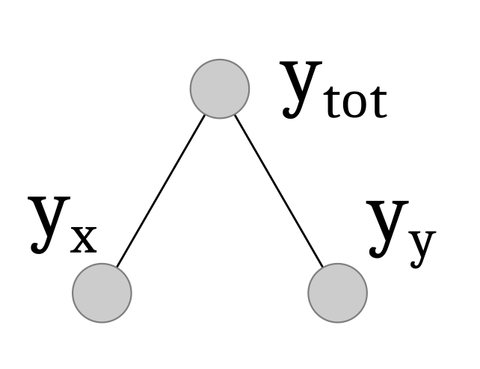
Hierarchical setting - A simple example
The most used linear subspace is the one generated by partial summation of some of a group of base forecasts.
Let’s call the set of bottom time series whose aggregation generates the set of upper level time series , for a total of time series
The aggregating structure of the hierarchy on the right can be encoded in a summation matrix :
All the observed samples of lie on the plane defined by , that is, the span of the column vectors
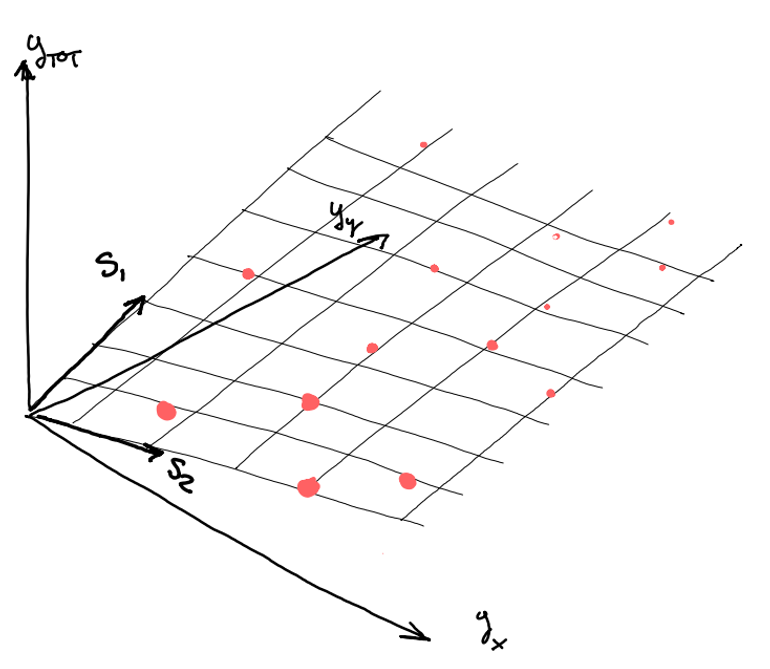
The matrix can be used to generate the whole set of time series starting only from the bottom time series . This is possible since the upper time series are produced by aggregation. You could also see this process as a decoding process (or a compression).
Linear reconciliation
Usually, the reconciliation of hierarchical time series is obtained through a linear transformation.
This linear transformation can be splitted in two (conceptual) parts:
: maps he whole forecasts vector into the reconciled set of bottom time series:
: obtains the aggregate-consistent forecasts for the whole hierarchy
BOTTOM-UP
If has zero entries for all the aggregated time series, the linear reconciliation is equivalent to a bottom-up approach: we just keep , discarding forecasts produced for the aggregations, and produce aggregate-consistent forecasts for aggregated quantities by summations.
TOP-DOWN
The top-down approach forecasts just the top-level time series and repartition them among the bottom time series using some heuristics
Orthogonal projection
The bottom-up and top-down approaches don’t use all the information contained in the base forecasts since they just use or to produce the corrected forecasts for the bottom time series
The information contained in the whole set of forecasts can be used by applying orthogonal projections. This guarantees that:
The correction displacement is minimal
The correction always reduces the total sum of squares error of the corrected forecasts
We can write point 1 as the following optimization problem:
Sketch of Proof of point 2 is a simple application of Pythagorean theorem:
No matter what our original prediction was, its distance from the ground truth is always greater than the distance of the projected forecasts from .
That is, the orthogonal projection onto can be obtained by linear regression, where the features are the columns of the summation matrix
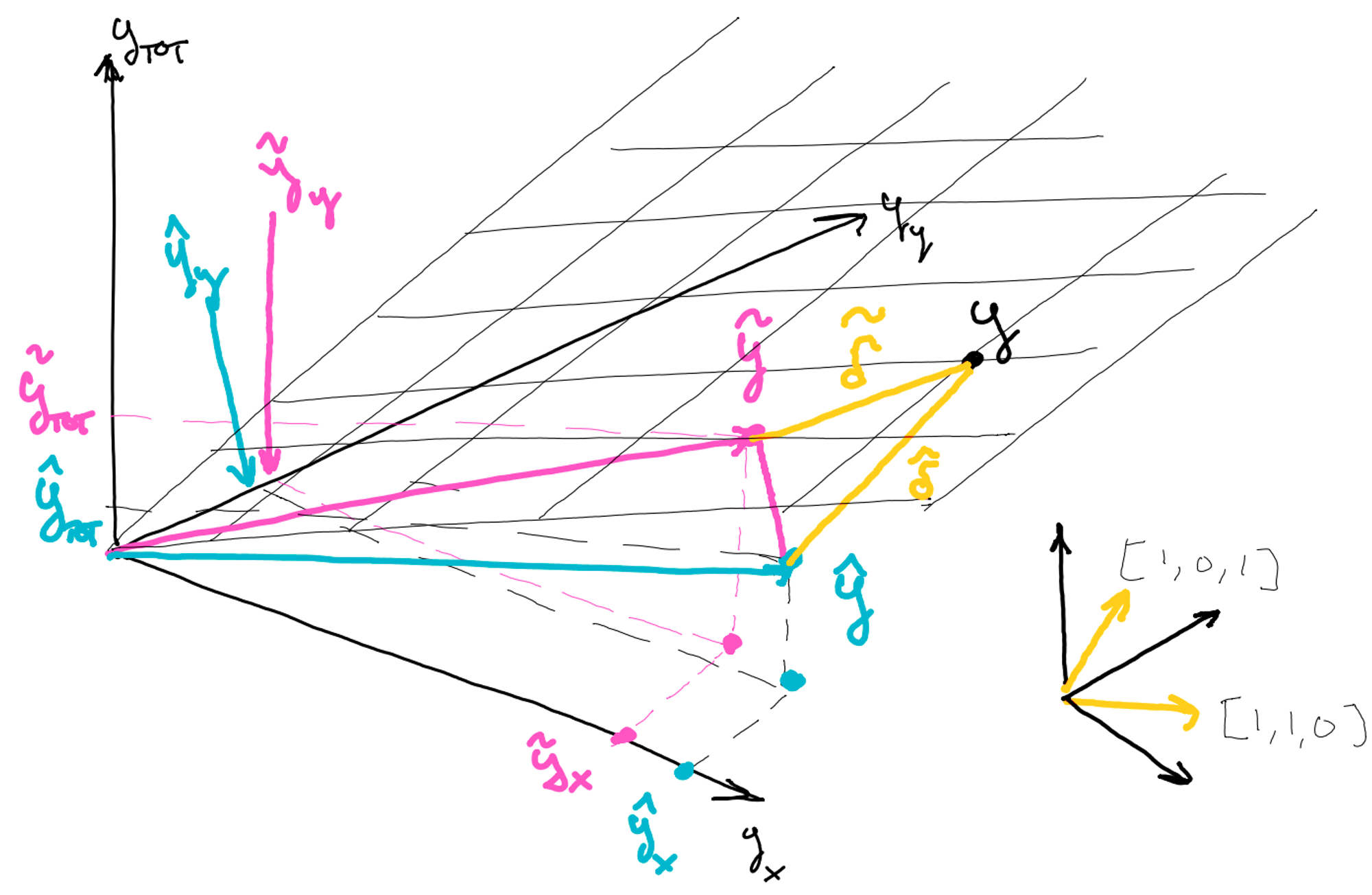
Oblique projection
Not all the series in the hierarchy should be treated equally (aggregations have bigger magnitudes)
Error correlation could be present
These factors can be taken into account if we apply generalized least squares, using the cross-covariance matrix of the forecasts’ errors.
GEOMETRIC INTERPRETATION
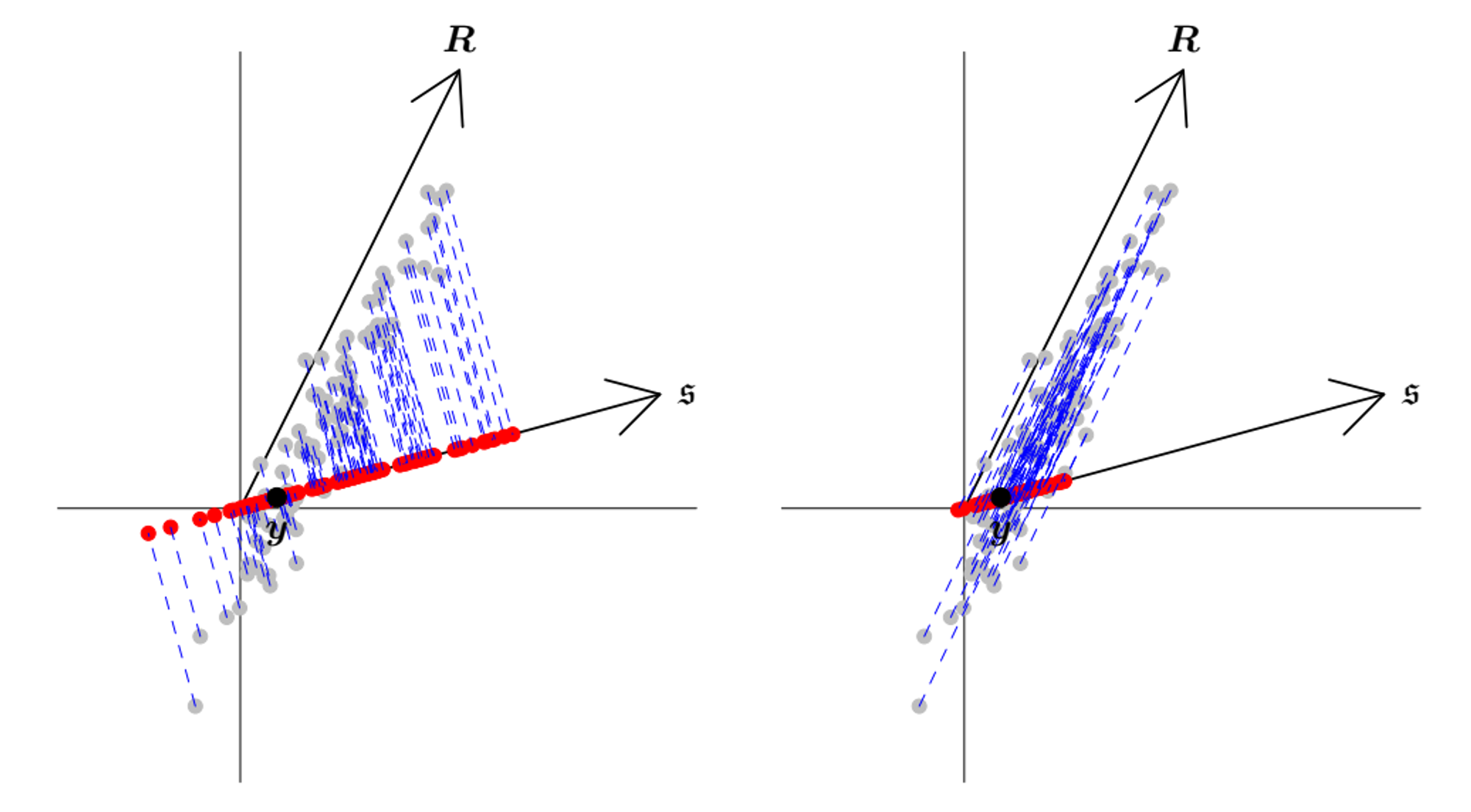
Left: orthogonal projection into the coherent subspace. Right: oblique projection using the observed more likely direction of the error. From A. Pantagiotelis et al., Forecast reconciliation: A geometric view with new insights on bias correction
MATHEMATICAL INTERPRETATION
If we pre-transform the summation matrix columns and the base forecasts as :
The above expression reduces to an orthogonal projection → it can be seen as an orthogonal projection on a transformed space.